Problem set 2¶
155 pts¶
For problems 1, 2, 4: all functions that you are asked to implement, you have to complete in separate file pset2.py, where we provide signatures of the required functions . Also only this py-file you have to submit in the bot to check correctness of your implementations.
For problem 3: see instructions in text
Problem 1 (LU decomposition) 35 pts¶
1. LU for band matrices¶
The complexity to find an LU decomposition of a dense $n\times n$ matrix is $\mathcal{O}(n^3)$. Significant reduction in complexity can be achieved if the matrix has a certain structure, e.g. it is sparse. In the following task we consider an important example of $LU$ for a special type of sparse matrices –– band matrices with the bandwidth $m$ equal to 3 or 5 which called tridiagonal and pentadiagonal respectively.
- (5 pts) Write a function
band_lu(diag_broadcast, n)which computes LU decomposition for tridiagonal or pentadiagonal matrix with given diagonal values. For example, input parametres(diag_broadcast = [1,-2,1], n = 4)mean that we need to find LU decomposition for the triangular matrix of the form:
$$A = \begin{pmatrix} -2 & 1 & 0 & 0\\ 1 & -2 & 1 & 0 \\ 0 & 1 & -2 & 1 \\ 0 & 0 & 1 & -2 \\ \end{pmatrix}.$$
As an output it is considered to make L and U - 2D arrays representing diagonals in factors $L$ (L[0] keeps first lower diagonal, L[1] keeps second lower, ...), and $U$ (U[:,0] keeps main diagonal, U[:,1] keeps first upper, ...). More details you can find in comments to the corresponding function in pset2.py
- (2 pts) Compare execution time of the band LU decomposition using standard function from
scipy, i.e. which takes the whole matrix and does not know about its special structure, and band decomposition of yours implementation. Comment on the results.
# Implement function in the ```pset2.py``` file
from pset2 import band_lu
from scipy.sparse import diags # can be used with broadcasting of scalars if desired dimensions are large
import numpy as np
# Your code is here
2. Completing the proof of existence of LU¶
Some details in lecture proofs about $LU$ were omitted. Let us complete them here.
- (5 pts) Prove that if $LU$ decomposition exists, then matrix is strictly regular.
- (5 pts) Prove that if $A$ is a strictly regular matrix, then $A_1 = D - \frac 1a b c^T$ (see lectures for notations) is also strictly regular.
# Your solution is here
3. Stability of LU¶
Let $A = \begin{pmatrix} \varepsilon & 1 & 0\\ 1 & 1 & 1 \\ 0 & 1 & 1 \end{pmatrix}.$
- (5 pts) Find analytically LU decomposition with and without pivoting for the matrix $A$.
- (3 pts) Explain, why can the LU decomposition fail to approximate factors $L$ and $U$ for $|\varepsilon|\ll 1$ in computer arithmetic?
# Your solution is here
4. Block LU¶
Let $A = \begin{bmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{bmatrix}$ be a block matrix. The goal is to solve the linear system
$$ \begin{bmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{bmatrix} \begin{bmatrix} u_1 \\ u_2 \end{bmatrix} = \begin{bmatrix} f_1 \\ f_2 \end{bmatrix}. $$
- (2 pts) Using block elimination find matrix $S$ and right-hand side $\hat{f_2}$ so that $u_2$ can be found from $S u_2 = \hat{f_2}$. Note that the matrix $S$ is called Schur complement of the block $A_{11}$.
- (4 pts) Using Schur complement properties prove that
$$\det(X+AB) = \det(X)\det(I+BX^{-1}A), $$
where $X$ - nonsingular square matrix.
- (4 pts) Let matrix $F \in \mathbb{R}^{m \times n}$ and $G \in \mathbb{R}^{n \times m}$. Prove that
$$\det(I_m - FG) = \det(I_n - GF).$$
# Your solution is here
Problem 2 (QR decomposition) 30 pts¶
1. Standard Gram-Schmidt algorithm¶
Our goal is to orthogonalize a system of linearly independent vectors $v_1,\dots,v_n$. The standard algorithm for this task is the Gram-Schmidt process:
$$ \begin{split} u_1 &= v_1, \\ u_2 &= v_2 - \frac{(v_2, u_1)}{(u_1, u_1)} u_1, \\ \dots \\ u_n &= v_n - \frac{(v_n, u_1)}{(u_1, u_1)} u_1 - \frac{(v_n, u_2)}{(u_2, u_2)} u_2 - \dots - \frac{(v_n, u_{n-1})}{(u_{n-1}, u_{n-1})} u_{n-1}. \end{split} $$
Obtained $u_1, \dots, u_n$ are orthogonal vectors in exact arithmetics. Then to make the system orthonormal you should divide each of the vectors by its norm: $u_i := u_i/\|u_i\|$. The Gram-Schmidt process can be considered as a QR decomposition. Let us show that.
(2 pts) Write out what is matrices $Q$ and $R$ obtained in the process above.
(5 pts) Implement in the
pset2.pythe described Gram-Schmidt algorithm as a functiongram_schmidt_qr(A)that takes a rectangular matrixAand outputsQ,R.(3 pts) Create a square Vandermonde matrix $V\in\mathbb{R}^{n\times n},\ n = 20$ defined by the vector $x$:
x = np.linspace(0,1,n)(components of $x$ are spaced uniformly between 0 and 1). The loss of orthogonality can be described by the following error: $\|Q^{\top}Q-I\|_2$, where $Q^{\top}Q$ is called a Gram matrix. Compute QR decomposition of the created matrix $V$ with function that you have implemented and calculate error $\|Q^{\top}Q-I\|_2$. Comment on the result.(5 pts) The observed loss of orthogonality is a problem of this particular algorithm. Luckily, there is a simple improvement to the algorithm above that reduces the loss of orthogonality. Implement this modification in the
pset2.pyas a functionmodified_gram_schmidt_qr(A)such that input and output are similar togram_schmidt_qr(A).- (3 pts) Compute QR decomposition of the matrix $V$ from the previous task with the function
modified_gram_schmidt_qr(A). Compute error $\|Q^{\top}Q-I\|_2$. Compare this error to the error obtained with a "pure" Gram-Schmidt and comment on the result.
# Implement the functions in the ```pset2.py``` file
from pset2 import gram_schmidt_qr
from pset2 import modified_gram_schmidt_qr
# Your code is here
2. Householder QR (10 pts)¶
- (7 pts) Implement algorithm for computing QR decomposition based on Householder reflections as a function
householder_qr(A)that takes a rectangular matrixAand outputsQ,R.
- (2 pts) Apply it to the Vandermonde matrix $V$ created above. Print out the error $\|Q^{\top}Q-I\|_2$, where $Q$ is given by
householder_qr(A). Compare it to the corresponding results of Gram-Schmidt and modified Gram-Schmidt algorithms and comment on it.
- (3 pts) For values of $n = \{2,25,100,250,500\}$, create a $B\in\mathbb{R}^{n\times n}$ and an upper triangular matrix $R\in\mathbb{R}^{n\times n}$ both filled with standard normal entries. Use
numpy(orscipy) built-in QR decomposition function to obtain a random orthogonal matrix $Q$ from the decomposition of $B$. Then compute $A = QR$ and apply your Gram-Schmidt and Householder algorithms to find the $Q$ and $R$ factors of $A$ – denoted as $\hat{Q}$ and $\hat{R}$. Calculate relative errors $$\frac{\|R-\hat{R}\|_2}{\|R\|_2}, \frac{\|Q-\hat{Q}\|_2}{\|Q\|_2}, \frac{\|A-\hat{Q}\hat{R}\|_2}{\|A\|_2}$$ for each value of $n$ and for both algorithms. Note: scale (multiply corresponding rows/columns by -1) $Q, R,\hat{Q},\hat{R}$ such that diagonal elements of $R$ and $\hat{R}$ be positive.- Comment on the relative errors in $Q$ and $R$ (forward error) compared to ones in $QR$ (backward error).
- Comment on the backward error obtained for Gram-Schmidt compared to Householder.
# Implement the function in the pset2.py file
from pset2 import householder_qr
# Your code is here
Problem 3 (Word2Vec as Matrix Factorization) 45 pts¶
In this assignment you are supposed to apply SVD to training your own word embedding model which maps English words to vectors of real numbers.
Skip-Gram Negative Sampling (SGNS) word embedding model, commonly known as word2vec (Mikolov et al., 2013), is usually optimized by stochastic gradient descent. However, the optimization of SGNS objective can be viewed as implicit matrix factorization objective as was shown in (Levy and Goldberg, 2015).
1. Notation¶
Assume we have a text corpus given as a sequence of words $\{w_1,w_2,\dots,w_n\}$ where $n$ may be larger than $10^{12}$ and $w_i \in \mathcal{V}$ belongs to a vocabulary of words $\mathcal{V}$. A word $c \in \mathcal{V}$ is called a context of word $w_i$ if they are found together in the text. More formally, given some measure $L$ of closeness between two words (typical choice is $L=2$), a word $c \in \mathcal{V}$ is called a context if $c \in \{w_{i-L}, \dots, w_{i-1}, w_{i+1}, \dots, w_{i+L} \}$ Let $\mathbf{w},\mathbf{c}\in\mathbb{R}^d$ be the word embeddings of word $w$ and context $c$, respectively. Assume they are specified by the mapping $\Phi:\mathcal{V}\rightarrow\mathbb{R}^d$, so $\mathbf{w}=\Phi(w)$. The ultimate goal of SGNS word embedding model is to fit a good mapping $\Phi$.
Let $\mathcal{D}$ be a multiset of all word-contexts pairs observed in the corpus. In the SGNS model, the probability that word-context pair $(w,c)$ is observed in the corpus is modeled as the following distribution:
$$ P(\#(w,c)\neq 0|w,c) = \sigma(\mathbf{w}^\top \mathbf{c}) = \frac{1}{1 + \exp(-\mathbf{w}^\top \mathbf{c})}, $$
where $\#(w,c)$ is the number of times the pair $(w,c)$ appears in $\mathcal{D}$ and $\mathbf{w}^\top\mathbf{c}$ is the scalar product of vectors $\mathbf{w}$ and $\mathbf{c}$. Two important quantities which we will also use further are the number of times the word $w$ and the context $c$ appear in $\mathcal{D}$, which can be computed as
$$ \#(w) = \sum_{c\in\mathcal{V}} \#(w,c), \quad \#(c) = \sum_{w\in\mathcal{V}} \#(w,c). $$
2. Optimization objective¶
Vanilla word embedding models are trained by maximizing log-likelihood of observed word-context pairs, namely
$$ \mathcal{L} = \sum_{w \in \mathcal{V}} \sum_{c \in \mathcal{V}} \#(w,c) \log \sigma(\mathbf{w}^\top\mathbf{c}) \rightarrow \max_{\mathbf{w},\mathbf{c} \in \mathbb{R}^d}. $$
Skip-Gram Negative Sampling approach modifies the objective by additionally minimizing the log-likelihood of random word-context pairs, so called negative samples. This idea incorporates some useful linguistic information that some number ($k$, usually $k=5$) of word-context pairs are not found together in the corpus which usually results in word embeddings of higher quality. The resulting optimization problem is
$$ \mathcal{L} = \sum_{w \in \mathcal{V}} \sum_{c \in \mathcal{V}} \left( \#(w,c) \log \sigma(\mathbf{w}^\top\mathbf{c}) + k \cdot \mathbb{E}_{c'\sim P_\mathcal{D}} \log \sigma (-\mathbf{w}^\top\mathbf{c}) \right) \rightarrow \max_{\mathbf{w},\mathbf{c} \in \mathbb{R}^d}, $$
where $P_\mathcal{D}(c)=\frac{\#(c)}{|\mathcal{D}|}$ is a probability distribution over word contexts from which negative samples are drawn.
Levy and Goldberg, 2015 showed that this objective can be equivalently written as
$$ \mathcal{L} = \sum_{w \in \mathcal{V}} \sum_{c \in \mathcal{V}} f(w,c) = \sum_{w \in \mathcal{V}} \sum_{c \in \mathcal{V}} \left( \#(w,c) \log \sigma(\mathbf{w}^\top\mathbf{c}) + \frac{k\cdot\#(w)\cdot\#(c)}{|\mathcal{D}|} \log \sigma (-\mathbf{w}^\top\mathbf{c}) \right) \rightarrow \max_{\mathbf{w},\mathbf{c} \in \mathbb{R}^d}, $$
A crucial observation is that this loss function depends only on the scalar product $\mathbf{w}^\top\mathbf{c}$ but not on embedding $\mathbf{w}$ and $\mathbf{c}$ separately.
3. Matrix factorization problem statement¶
Let $|\mathcal{V}|=m$, $W \in \mathbb{R}^{m\times d}$ and $C \in \mathbb{R}^{m\times d}$ be matrices, where each row $\mathbf{w}\in\mathbb{R}^d$ of matrix $W$ is the word embedding of the corresponding word $w$ and each row $\mathbf{c}\in\mathbb{R}^d$ of matrix $C$ is the context embedding of the corresponding context $c$. SGNS embeds both words and their contexts into a low-dimensional space $\mathbb{R}^d$, resulting in the word and context matrices $W$ and $C$. The rows of matrix $W$ are typically used in NLP tasks (such as computing word similarities) while $C$ is ignored. It is nonetheless instructive to consider the product $W^\top C = M$. Viewed this way, SGNS can be described as factorizing an implicit matrix $M$ of dimensions $m \times m$ into two smaller matrices.
Which matrix is being factorized? A matrix entry $M_{wc}$ corresponds to the dot product $\mathbf{w}^\top\mathbf{c}$ . Thus, SGNS is factorizing a matrix in which each row corresponds to a word $w \in \mathcal{V}$ , each column corresponds to a context $c \in \mathcal{V}$, and each cell contains a quantity $f(w,c)$ reflecting the strength of association between that particular word-context pair. Such word-context association matrices are very common in the NLP and word-similarity literature. That said, the objective of SGNS does not explicitly state what this association metric is. What can we say about the association function $f(w,c)$? In other words, which matrix is SGNS factorizing? Below you will find the answers.
Task 1 (theoretical) 5 pts¶
Solve SGNS optimization problem with respect to the $\mathbf{w}^\top\mathbf{c}$ and show that the matrix being factorized is
$$ M_{wc} = \mathbf{w}^\top\mathbf{c} = \log \left( \frac{\#(w,c) \cdot |\mathcal{D}|}{k\cdot\#(w)\cdot\#(c)} \right) $$
Hint: Denote $x=\mathbf{w}^\top\mathbf{c}$, rewrite SGNG optimization problem in terms of $x$ and solve it.
Note: This matrix is called Shifted Pointwise Mutual Information (SPMI) matrix, as its elements can be written as
$$ \text{SPMI}(w,c) = M_{wc} = \mathbf{w}^\top\mathbf{c} = \text{PMI}(w,c) - \log k $$
and $\text{PMI}(w,c) = \log \left( \frac{\#(w,c) \cdot |\mathcal{D}|}{\#(w)\cdot\#(c)} \right)$ is the well-known pointwise mutual information of $(w,c)$.
# Your proof is here
Task 2 (practical) 40 pts¶
import os
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from scipy.sparse.linalg import svds
- Download dataset enwik8 of compressed Wikipedia articles and preprocess raw data with Perl script main_.pl. This script will clean all unnecessary symbols, make all words to lowercase, and produce only sentences with words.
wget http://mattmahoney.net/dc/enwik8.zip unzip enwik8.zip mkdir data perl main_.pl enwik8 > data/enwik8.txt
# Load enwik 8
import re
file = open("data/enwik8.txt", "r")
doclist = [line for line in file]
docstr = ''.join(doclist)
sentences = re.split(r'[.!?]', docstr)
sentences = [sentence.split() for sentence in sentences if len(sentence) > 1]
print (sentences[1249])
- Construct the word vocabulary from the obtained sentences which enumerates words which occur more than $r=200$ times in the corpus.
def create_vocabulary(sentences, r=200):
vocabulary = {}
# Your code is here
return vocabulary
vocab = create_vocabulary(sentences)
- Scan the text corpus with sliding window of size $5$ and step $1$ (which corresponds to $L$=2) and construct co-occurrence word-context matrix $D$ with elements $D_{wc}=\#(w,c)$. Please, ignore words which occur less than $r=200$ times, but include them into the sliding window. Please, see the graphical illustration of the procedure described.

def create_corpus_matrix(sentences, vocabulary):
# Your code is here
return corpus_matrix
D = create_corpus_matrix(sentences, vocab)
- To find good word embeddings, Levy and Goldberg, 2015 proposed to find rank-$d$ SVD of Shifted Positive Pointwise Mutual Information (SPPMI) matrix
$$ U \Sigma V^\top \approx \text{SPPMI}, $$
where $\text{SPPMI}(w, c) = \max\left(\text{SPMI}(w, c), 0 \right)$ and $\text{SPMI}(w, c)$ is the element of the matrix $\text{SPPMI}$ at position $(w, c)$. Then use $W=U\sqrt{\Sigma}$ as word embedding matrix. Your task is to reproduce their results. Write function constructs $\text{SPPMI}$ matrix, computes its SVD and produces word-vectors matrix $W$. Pay attention that $\text{SPPMI}$ matrix is sparse!
def compute_embeddings(D, k, d=200):
# Your code is here
return embedding_matrix
k = 5 # negative sampling parameter
W = compute_embeddings(D, k)
- Write class WordVectors using provided template.
class WordVectors:
def __init__(self, vocabulary, embedding_matrix):
self.vocab = vocabulary
self.W = embedding_matrix
self.inv_vocab = {v: k for k, v in self.vocab.items()}
def word_vector(self, word):
"""
Takes word and returns its word vector.
"""
# Your code is here
return word_vector
def nearest_words(self, word, top_n=10):
"""
Takes word from the vocabulary and returns its top_n
nearest neighbors in terms of cosine similarity.
"""
# Your code is here
return neighbors
model = WordVectors(vocab, W)
model.nearest_words("anarchism")
model.nearest_words("ussr")
model.nearest_words("rap")
- Calculate top 10 nearest neighbours with the corresponding cosine similarities for the words {numerical, linear, algebra} and insert them in the correspoding functions in
pset2.py.
Problem 4 (eigenvalues) 45 pts¶
1. Theoretical tasks¶
(5 pts) Prove that normal matrix is Hermitian iff its eigenvalues are real. Prove that normal matrix is unitary iff its eigenvalues satisfy $|\lambda| = 1$.
(5 pts) The following problem illustrates instability of the Jordan form. Find theoretically the eigenvalues of the perturbed Jordan block:
$$ J(\varepsilon) = \begin{bmatrix} \lambda & 1 & & & 0 \\ & \lambda & 1 & & \\ & & \ddots & \ddots & \\ & & & \lambda & 1 \\ \varepsilon & & & & \lambda \\ \end{bmatrix}_{n\times n} $$
Comment how eigenvalues of $J(0)$ are perturbed for large $n$.
2. PageRank¶
Damping factor importance¶
(5 pts) Write the function
pagerank_matrix(G)that takes an adjacency matrix $G$ (in both sparse and dense formats) as an input and outputs the corresponding PageRank matrix $A$.(3 pts) Find PageRank matrix $A$ that corresponds to the following graph:
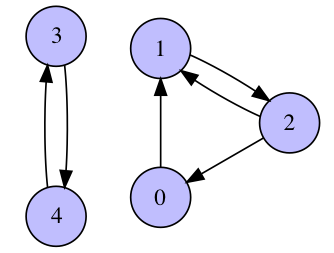 What is its largest eigenvalue? What multiplicity does it have?
What is its largest eigenvalue? What multiplicity does it have?
- (5 pts) Implement the power method for a given matrix $A$, an initial guess $x_0$ and a number of iterations
num_iter. It should be organized as a functionpower_method(A, x0, num_iter)that outputs approximation to eigenvector $x$, eigenvalue $\lambda$ and history of residuals $\{\|Ax_k - \lambda_k x_k\|_2\}$. Make sure that the method conveges to the correct solution on a matrix $\begin{bmatrix} 2 & -1 \\ -1 & 2 \end{bmatrix}$ which is known to have the largest eigenvalue equal to $3$.
- (2 pts) Run the power method for the graph presented above and plot residuals $\|Ax_k - \lambda_k x_k\|_2$ as a function of $k$ for
num_iter=100and random initial guessx0. Explain the absence of convergence.
- (2 pts) Consider the same graph, but with a directed edge that goes from the node 3 to the node 4 being removed. Plot residuals as in the previous task and discuss the convergence. Now, run the power method with
num_iter=100for 10 different initial guesses and print/plot the resulting approximated eigenvectors. Why do they depend on the initial guess?
In order to avoid this problem Larry Page and Sergey Brin proposed to use the following regularization technique:
$$ A_d = dA + \frac{1-d}{N} \begin{pmatrix} 1 & \dots & 1 \\ \vdots & & \vdots \\ 1 & \dots & 1 \end{pmatrix}, $$
where $d$ is a small parameter in $[0,1]$ (typically $d=0.85$), which is called damping factor, $A$ is of size $N\times N$. Now $A_d$ is the matrix with multiplicity of the largest eigenvalue equal to 1. Recall that computing the eigenvector of the PageRank matrix, which corresponds to the largest eigenvalue, has the following interpretation. Consider a person who stays in a random node of a graph (i.e. opens a random web page); at each step s/he follows one of the outcoming edges uniformly at random (i.e. opens one of the links). So the person randomly walks through the graph and the eigenvector we are looking for is exactly his/her stationary distribution — for each node it tells you the probability of visiting this particular node. Therefore, if the person has started from a part of the graph which is not connected with the other part, he will never get there. In the regularized model, the person at each step follows one of the outcoming links with probability $d$ OR teleports to a random node from the whole graph with probability $(1-d)$.
(2 pts) Now, run the power method with $A_d$ and plot residuals $\|A_d x_k - \lambda_k x_k\|_2$ as a function of $k$ for $d=0.97$,
num_iter=100and a random initial guessx0.(5 pts) Find the second largest in the absolute value eigenvalue of the obtained matrix $A_d$. How and why is it connected to the damping factor $d$? What is the convergence rate of the PageRank algorithm when using damping factor?
Usually, graphs that arise in various areas are sparse (social, web, road networks, etc.) and, thus, computation of a matrix-vector product for corresponding PageRank matrix $A$ is much cheaper than $\mathcal{O}(N^2)$. However, if $A_d$ is calculated directly, it becomes dense and, therefore, $\mathcal{O}(N^2)$ cost grows prohibitively large for big $N$.
(2 pts) Implement fast matrix-vector product for $A_d$ as a function
pagerank_matvec(A, d, x), which takes a PageRank matrix $A$ (in sparse format, e.g.,csr_matrix), damping factor $d$ and a vector $x$ as an input and returns $A_dx$ as an output.(1 pts) Generate a random adjacency matrix of size $10000 \times 10000$ with only 100 non-zero elements and compare
pagerank_matvecperformance with direct evaluation of $A_dx$.
# implement the functions in the pset2.py file
from pset2 import pagerank_matrix, power_method, pagerank_matvec
# Your code is here
DBLP: computer science bibliography¶
Download the dataset from here, unzip it and put dblp_authors.npz and dblp_graph.npz in the same folder with this notebook. Each value (author name) from dblp_authors.npz corresponds to the row/column of the matrix from dblp_graph.npz. Value at row i and column j of the matrix from dblp_graph.npz corresponds to the number of times author i cited papers of the author j. Let us now find the most significant scientists according to PageRank model over DBLP data.
- (4 pts) Load the weighted adjacency matrix and the authors list into Python using
load_dblp(...)function. Print its density (fraction of nonzero elements). Find top-10 most cited authors from the weighted adjacency matrix. Now, make all the weights of the adjacency matrix equal to 1 for simplicity (consider only existence of connection between authors, not its weight). Obtain the PageRank matrix $A$ from the adjacency matrix and verify that it is stochastic.
- (1 pts) In order to provide
pagerank_matvecto yourpower_method(without rewriting it) for fast calculation of $A_dx$, you can create aLinearOperator:CallingL = scipy.sparse.linalg.LinearOperator(A.shape, matvec=lambda x, A=A, d=d: pagerank_matvec(A, d, x))
L@xorL.dot(x)will result in calculation ofpagerank_matvec(A, d, x)and, thus, you can plug $L$ instead of the matrix $A$ in thepower_methoddirectly. Note: though in the previous subtask graph was very small (so you could disparage fast matvec implementation), here it is very large (but sparse), so that direct evaluation of $A_dx$ will require $\sim 10^{12}$ matrix elements to store - good luck with that (^_<).
- (2 pts) Run the power method starting from the vector of all ones and plot residuals $\|A_dx_k - \lambda_k x_k\|_2$ as a function of $k$ for $d=0.85$.
- (1 pts) Print names of the top-10 authors according to PageRank over DBLP when $d=0.85$. Comment on your findings.
from scipy.sparse import load_npz
import numpy as np
def load_dblp(path_auth, path_graph):
G = load_npz(path_graph).astype(float)
with np.load(path_auth) as data: authors = data['authors']
return G, authors
G, authors = load_dblp('dblp_authors.npz', 'dblp_graph.npz')
# Your code is here